컴퓨터는 데이터를 볼때 0과 1로 해석하여 봅니다.
이 포스팅에서는 숫자,문자와 같은것을 컴퓨터가 어떻게 변환해서 보는지 공부해봅시다.
0과 1로 숫자를 보는법
수학에서 n진법라는 개념이 있습니다.
이를테면, 10진법은 우리가 현실에서 사용하는 0 ~ 9 까지의 숫자이후 자리올림을 하는것이고,
2진법이라면 0 ~ 1 까지 숫자이후 자리올림을 하는 것 입니다.
일반적인 정수를 만약 계산한다하면 별다른 문제가 발생하지 않지만 소수를 계산하면 문제가 생깁니다.

정수끼리의 계산은 TRUE가 나오는 반면 소수의 계산은 저희의 상식으로 볼땐 맞는데 컴퓨터는 FALSE라고 합니다
왜 이런일이 일어났을까요?
컴퓨터는 소수점을 나타낼 때 부동소수점이라는 개념을 사용합니다.
부동소수점이란 필요에 따라 소수점을 유동적으로 이동시키는 특징을 지녔는데요.
예를들어 101010.101010 이라는 소수를 부동소수점을 사용하여 표현해보면퓨터는 데이터를 볼때 0과 1로 해석하여 봅니다.

이렇게 됩니다. 보시면 소수점이 옮겨진건 알겠는데 왜 X기호 옆에 저런 숫자가 붙는가 하면
우선 숫자 2는 2진법에대한 계산이어서 2를 적습니다. 만약 10진법에대한 부동소수점 계산이라면 10을 적습니다.
그리고 거듭제곱처럼 적혀있는 -3은 지수라고합니다.
지수는 소수점의 움직임에따라 양수가 될 수도 있고 숫자가 바뀔수 도 있습니다.
지수가 양수일 때는 소수점이 왼쪽으로 움직이며 옮겨진 소수점 위치만큼 숫자가 증가합니다.
반대로, 지수가 음수일 때 소수점이 오른쪽으로 움직이며 옮겨진 소수점위치만큼 숫자가 증가합니다.
이렇게 소수점이 옮겨진 소스는 가수라고 부릅니다.
컴퓨터는 2진수의 지수와 가수를 IEEE754라는 방법으로 저장합니다.
여기서 문제가 발생합니다.
컴퓨터가 저장할 수있는 길이의 양은 정해져있는데 0.3333333333... 같은 무한소수가 나오거나 저장공간을 초과해버리는 숫자가 나오면 컴퓨터는 길이에 맞춰서 숫자를 자르게 됩니다.
때문에 소수의 계산은 부정확 해집니다.
0과 1로 문자를 읽는법
컴퓨터가 읽을 수 있는 문자들을 문자 집합이라고 합니다.
이 문자집합들을 컴퓨터가 이해할 수 있도록 바꾸는 것을 문자 인코딩이라하면 반대의 개념은 문자 디코딩이라고합니다.
기본적인 문자인코딩 방식으로는 ASCII방식이 있습니다.
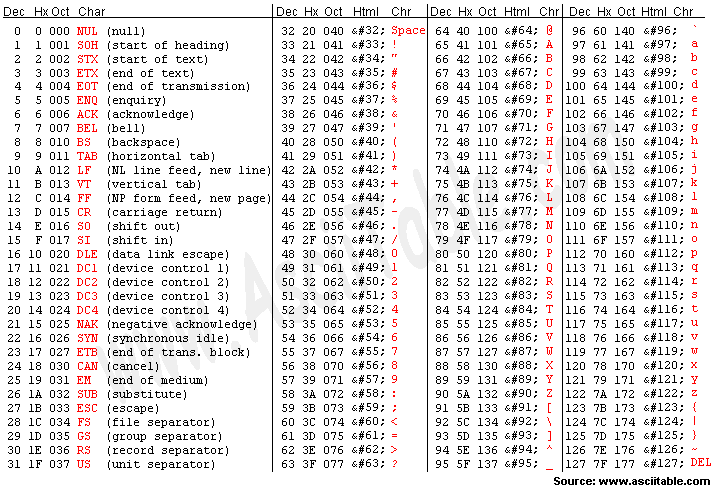
보시는 것 처럼 문자를 숫자에 대입해서 컴퓨터가 읽어들일 수 있게 만들어주는 방식 입니다.
그런데 이 코드표에는 문제가 있습니다. 바로 한국어나 일본어 아랍어와 같이 많은 문자들을 표현해내지 못했다는 것인데요.
그래서 가능한한 모든 문자를 컴퓨터가 읽어들일 수 있게 유니코드라는 것이 나왔습니다.
또한 문자뿐만아니라 특수기호나 이모티콘등 여러가지를 표현할 수 있는 문자집합이어서 오늘날 까지도 잘 쓰고있습니다.
이 유니코드를 인코딩 하는 방법으로 UTF-8, UTF-16, UTF-32와 같은 인코딩 방식이 있습니다.
용도마다 어떤 인코딩 방식을 쓰느냐는 다르지만, 기본적으로 UTF-8을 사용합니다.
이러한 인코딩 방식을 가변길이 인코딩이라고부릅니다
'Computer Science' 카테고리의 다른 글
| [CS] 해시 테이블은 뭘까 (1) | 2025.07.03 |
|---|---|
| [CS] 보조기억장치와 GPU (1) | 2025.06.08 |
| [CS] 메모리 (1) | 2025.06.07 |
| [CS] CPU (0) | 2025.06.03 |
| [CS] 컴퓨터 하드웨어와 역할 (0) | 2025.04.04 |


